
Growth Design 101: How to Run Product Experiments to Improve KPIs
Become a better designer by learning how to run growth experiments that actually move product metrics.

Introductions
One of the most powerful approaches to growth design is using a series of structured and intentional in-product experiments to make small but impactful changes across the entire user experience. For instance, changing the position of a button or rewriting a headline could significantly impact important metrics and create tremendous business value. However, how do we come up with the right design tweaks to make? How do we ensure metrics are moving in the right direction? When do we know we're come up with the best feasible solution? I'll explain all of this in this note.
How Might We…
Like in scientific research, all experiments should start with a good question. Good questions are derived from problem statements, encapsulate opportunities, and have a direct correlation with meaningful "key performance indicators" (KPIs.) For instance, one of the most critical KPIs businesses care about is the "conversion rate" (CVR), as it relates to revenue generated (e.g., checkout rates) or user acquisition (e.g., sign-up rates.) A great framework to articulate questions is "How Might We" (HMWs.) For example, an HMW might read: "How might we increase the conversion rate on the checkout page."
Hypotheses
Good research questions allow us to come up with corresponding hypotheses and experiments. In this context, a hypothesis is a testable statement that describes the relationship between an independent variable (IV) and a dependent variable (DV). You generally want to generate multiple hypotheses for each research question or HMW. The IV is the variable we have influence over, the "thing we can tweak." The DV is the variable we want to influence, which is the metric we want to move.
Hypotheses should be articulated as a hypothesis statement which takes the form of “If _________ (IV), then, _________ (DV). With our example above, the variable we want to influence is the conversion rate (CVR), and we might have a couple of ideas on how to do that. For instance, perhaps we think the checkout button isn't prominent enough, or there are too many distracting "call-to-action" (CTA) buttons on the screen. If we were to convert those into proper hypothesis statements, they would read: (1) If we make the checkout button more prominent, then the CVR on the checkout page will increase, and (2) If we remove the non-essential CTA buttons, then the CVR on the checkout page will increase.
Assumptions
In most cases, you'll end up with way too many hypotheses to feasibly validate given limited time and resources. What I like to do is add an assumption "because" extension to the "if-then hypothesis statement." Instead, the statement would now take the form of “If _________ (IV), then, _________ (DV), because _________ (assumption).” The assumption would be based on all the research, data, and context you've gathered throughout this process. Let's rewrite our hypotheses with the assumption extension.
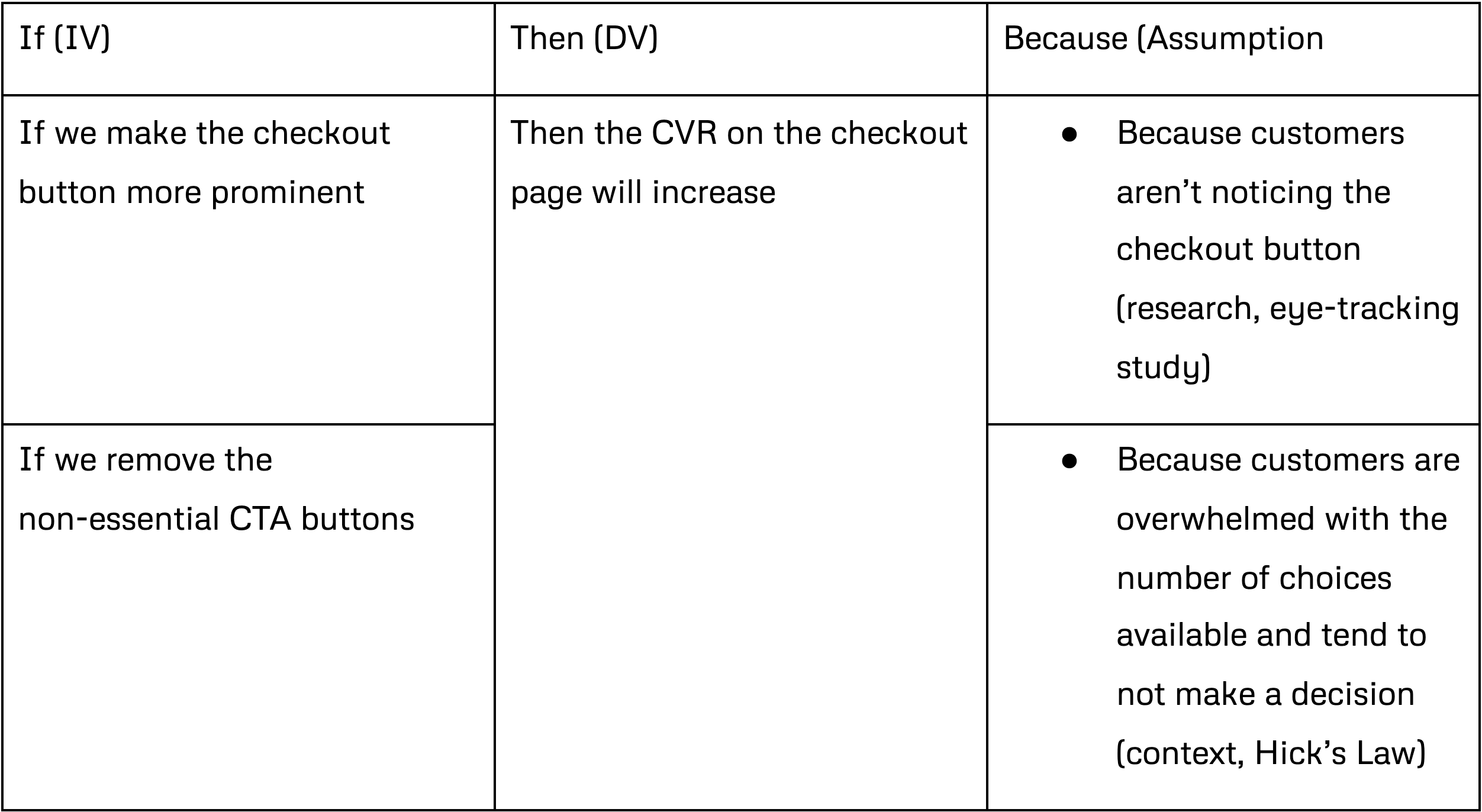
These examples are straightforward, so a single high confidence assumption is enough to move forward to the experiment phase. However, this might not always be the case. All assumptions have varying degrees of "risk" based on how confident you are. In general, researching and collecting data from competitors and adjacent products is cheaper than running the actual experiment itself. Therefore you should use the resources at your disposal to reduce the risk of your assumptions and run experiments that are more likely to yield a positive result (validated hypotheses).
Experiments
This is the foundation of all hypotheses; they need to be testable and infer a proposed relationship between the IV and the DV. Once you have a set of hypotheses, the next step is to create experiments for hypotheses worth validating. There is a hierarchical "tree" relationship between the question, the hypotheses, and the experiments, ranging from solution agnostic to solution specific.

When designing experiments, we want to introduce granular changes to the design to validate (or invalidate) each hypothesis. For example, for hypothesis (1): "If we make the checkout button more prominent, then the CVR on the checkout page will increase because customers aren't noticing the checkout button." the following experiments could be done: (1) make the button color contrast more with the background, (2) make the button larger, (3) increase the white space around the button, (4) make the button label bigger, (5) make the button label font bolder, etc.
As you can see, we can develop a wide range of experiments to validate the hypothesis. Again, this is where assumption confidence can be increased through research, data, and context to help you decide which experiment(s) to run first.
The Local Maxima Problem
Since our goal is to increase a KPI as much as possible, we shouldn't be satisfied with incremental improvements if we can make a multi-x improvement. A small incremental improvement is a "local maxima," whereas the absolute best possible improvement is the "global maxima."

For example, in our experiments above, they are all quite different and have the potential to hit the curve of the global maxima, in which case we can do multivariable testing to improve further. If all our experiments focused on changing the CTA button's color, then even if our hypothesis were validated, we would never reach the global maxima unless changing the color of the CTA button is the best possible improvement we could have made.
Experiment Design
Now that you have your experiments, you can't just implement the changes without setting up either an AB test or multivariate test. A hypothesis can only be validated when we can prove a causal relationship between the IV and DV without other factors in the mix (confounding variables.) If we shipped the experiment as is, we wouldn't be able to confirm it had a direct positive influence on the metric (IV) since confounding variables such as time and other features shipped during the experiment might have also influenced the IV. Therefore we need a "control" or baseline to measure our experiment (the "variant") against.
In practice, this would be an AB test where traffic is split between "A," the control or current experience, and "B," the variant or proposed experiment change (e.g., making the font bolder.) The exact split doesn't matter as long as the experiment runs long enough to reach statistical significance for both control and variant groups.
Multivariate testing is similar and can be considered multiple concurrent AB tests being all run on the same page simultaneously. This would be having "A" as the control, but having several different colors representing variants "B," "C," "D," etc.
Conclusion
In conclusion, the goal of experimentation is to achieve a business or product objective. Experiments operate on a micro-scale and won't create a successful product with PMF. It's more suited for mature products or products that need to grow their user base. Experiments are not about running tests for tests' sake or to tick a box in a framework checklist. All the experimentation should fit into the broader product vision.
Don’t forget to subscribe to get all the updates!
These emails might end up in your spam or promotions tab. To fix this, drag the emails back to the inbox or add ambitiousdesigner@substack.com to your contact list or send a reply.

If you found this useful, please consider sharing it with a friend or on social media. It’ll motivate me to write more and keep this going!